

Indexy SQL – mariadb
Jiří

1. 6. 2022 10:31:30
1. 6. 2022 10:31:30
TomasX
1. 6. 2022 11:00:11
1. 6. 2022 11:00:11
puhy.cz
1. 6. 2022 11:30:39
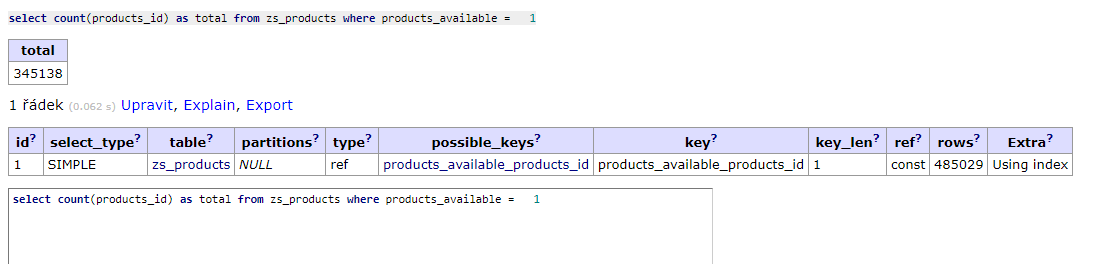 Jen ještě nějak zoptimalizovat tu aktualizaci, protože to samozřejmě trvá celkem dlouho, mám to takto:
Jen ještě nějak zoptimalizovat tu aktualizaci, protože to samozřejmě trvá celkem dlouho, mám to takto:
 Je tam nějaký zásadní prostor pro zlepšení?
Je tam nějaký zásadní prostor pro zlepšení?
1. 6. 2022 11:30:39
skorozacatecnik
1. 6. 2022 11:39:42
1. 6. 2022 11:39:42
TomasX
1. 6. 2022 11:50:36
1. 6. 2022 11:50:36
puhy.cz
1. 6. 2022 11:52:17
1. 6. 2022 11:52:17
TomasX
1. 6. 2022 12:00:06
1. 6. 2022 12:00:06
hm
1. 6. 2022 12:17:06
1. 6. 2022 12:17:06
puhy.cz
1. 6. 2022 12:56:28
 ---------- Příspěvek doplněn 01.06.2022 v 13:21 ----------
---------- Příspěvek doplněn 01.06.2022 v 13:21 ----------
1. 6. 2022 12:56:28
TomasX
1. 6. 2022 13:43:50
1. 6. 2022 13:43:50
puhy.cz
1. 6. 2022 13:50:19
 ---------- Příspěvek doplněn 01.06.2022 v 13:56 ----------Na vyhledávání používám sphinx, to by asi mohlo být dobré i na toto, ale zase to generování těch indexů není úplně rychlé a přijde mi, že pro stránkování produktů bude lepší zůstat u přímo u databáze. Případně šla by ta tabulka nějak podle products_name řadit opět občas cronem? Samozřejmě umím udělat order by, ale aby to tak i zůstalo?
---------- Příspěvek doplněn 01.06.2022 v 13:56 ----------Na vyhledávání používám sphinx, to by asi mohlo být dobré i na toto, ale zase to generování těch indexů není úplně rychlé a přijde mi, že pro stránkování produktů bude lepší zůstat u přímo u databáze. Případně šla by ta tabulka nějak podle products_name řadit opět občas cronem? Samozřejmě umím udělat order by, ale aby to tak i zůstalo?
1. 6. 2022 13:50:19
TomasX
1. 6. 2022 14:19:16
1. 6. 2022 14:19:16
puhy.cz
2. 6. 2022 09:48:23
2. 6. 2022 09:48:23
TomasX
2. 6. 2022 12:08:35
2. 6. 2022 12:08:35
puhy.cz
2. 6. 2022 13:05:58
2. 6. 2022 13:05:58
 Prodej
Více
Prodej
Více
E-shop s balkonovou fotovoltaikou
30 000 Kč
0 příhozů
starcom.cz – Cena možná i dohodou.
20 000 Kč
0 příhozů
Zastavarna.cz
96 999 Kč
0 příhozů
Prodám e-shop DreveneHodinky.eu a DreveneHodinky.sk
5 900 Kč
0 příhozů
⭐ Největší česká GASTROMAPA ⭐
9 900 Kč
0 příhozů