

Indexy SQL – mariadb
puhy.cz

26. 5. 2022 15:12:48
26. 5. 2022 15:12:48
TomasX
26. 5. 2022 15:26:29
26. 5. 2022 15:26:29
puhy.cz
27. 5. 2022 10:09:47
 Potřebuju ten dotaz ještě rozšířit. Původní je takovéto:
Výsledek cca 380000.
Zkouším něco jako:
Prostě produkty s nenulovým products_sklad, products_quantity a zároveň s odpovídajícím id kategorie. Toto vrací výsledek přes 1 000 000, správně je těch 380 000. products_id je ve všech třech tabulkách odpovídající a v rámci tabulky unikátní.
Myslel jsem, že by se mi hodil INTERSECT, ale ten mi vůbec nefunguje.
Potřebuju ten dotaz ještě rozšířit. Původní je takovéto:
Výsledek cca 380000.
Zkouším něco jako:
Prostě produkty s nenulovým products_sklad, products_quantity a zároveň s odpovídajícím id kategorie. Toto vrací výsledek přes 1 000 000, správně je těch 380 000. products_id je ve všech třech tabulkách odpovídající a v rámci tabulky unikátní.
Myslel jsem, že by se mi hodil INTERSECT, ale ten mi vůbec nefunguje.
27. 5. 2022 10:09:47
TomasX
27. 5. 2022 12:02:07
27. 5. 2022 12:02:07
puhy.cz
27. 5. 2022 12:37:54
27. 5. 2022 12:37:54
TomasX
27. 5. 2022 14:40:48
27. 5. 2022 14:40:48
takatom
27. 5. 2022 21:18:02
27. 5. 2022 21:18:02
TomasX
27. 5. 2022 21:42:00
27. 5. 2022 21:42:00
puhy.cz
31. 5. 2022 12:11:21
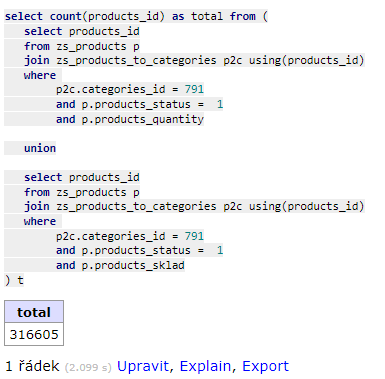
 Proč tam je u products sklad pořád where? Indexy mám co se týče products_quantity a products_sklad takto:
INDEX products_status, products_quantity
INDEX products_status, products_sklad
Napadá tě co je ještě šparně? Nebo na to mám jít přes trigger? Nebo si vytvořit sloupec products_avaiable a cronem jednou za minutu nastavovat 1, když bude products_status nebo products_quantity?---------- Příspěvek doplněn 31.05.2022 v 12:12 ----------
Proč tam je u products sklad pořád where? Indexy mám co se týče products_quantity a products_sklad takto:
INDEX products_status, products_quantity
INDEX products_status, products_sklad
Napadá tě co je ještě šparně? Nebo na to mám jít přes trigger? Nebo si vytvořit sloupec products_avaiable a cronem jednou za minutu nastavovat 1, když bude products_status nebo products_quantity?---------- Příspěvek doplněn 31.05.2022 v 12:12 ----------
31. 5. 2022 12:11:21
TomasX
31. 5. 2022 12:53:47
31. 5. 2022 12:53:47
skorozacatecnik
31. 5. 2022 14:07:00
31. 5. 2022 14:07:00
TomasX
31. 5. 2022 15:13:23
31. 5. 2022 15:13:23
puhy.cz
31. 5. 2022 16:00:40
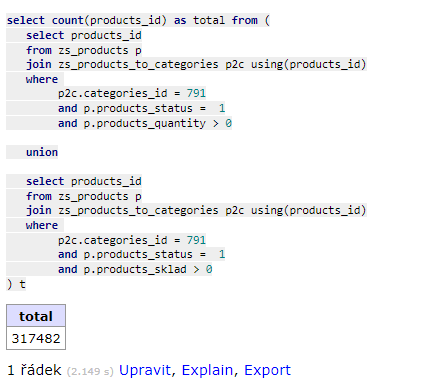
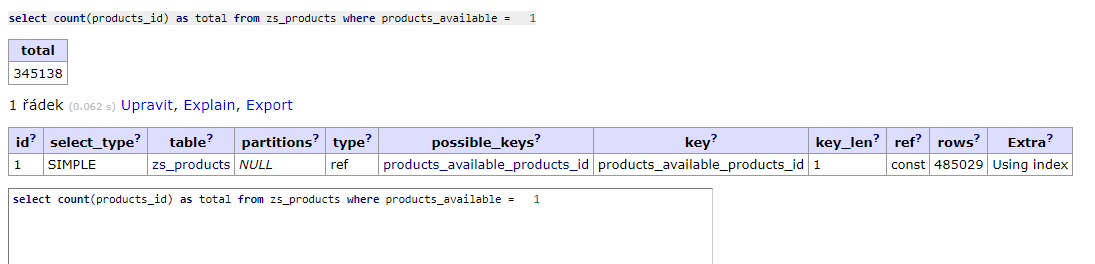
31. 5. 2022 16:00:40
TomasX
31. 5. 2022 19:11:37
31. 5. 2022 19:11:37
puhy.cz
1. 6. 2022 10:26:18
1. 6. 2022 10:26:18
 Prodej
Více
Prodej
Více
Adult Inzerce – pro pracující dívky
9 900 Kč
0 příhozů
Kreativní Omalovánky – prodej digitálních produktů
20 000 Kč
0 příhozů
💸 Srovnavač půjček abpujcky.cz
50 000 Kč
0 příhozů
P: databáze všech domén (všechny TLD) s automaticky aktualizovaným WHOIS
1 000 Kč
0 příhozů